






芯片资讯
- 发布日期:2024-01-30 06:37 点击次数:145
全球 CPU 商用市场基本被 Intel、AMD 两家垄断,国产 CPU 具备广阔拓展空间。CPU 目前从市场占有率来说,Intel 依靠其强大的 X86 生态体系和领先的制造能力,在通用 CPU 市场占据领先地位。2021 年,Intel 市场份额不低于 80%,AMD 近期追赶势头明显,其他厂商整体市场份额不超过 7%。
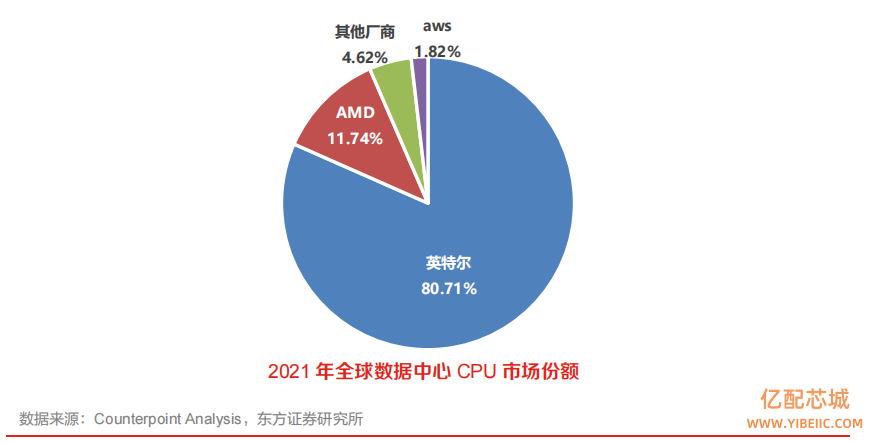
英特尔优势降低,数据中心领域集中度有所降低。2022 年,数据中心领域 Intel 市场占有率为71%,较 21 年下降 10pcts,AMD 22 年市占率快速提升 8pcts 至 20%,亚马逊、Ampere 等新兴玩家份额快速提升,给总计份额不足 5%的国产厂商发展带来了借鉴意义。
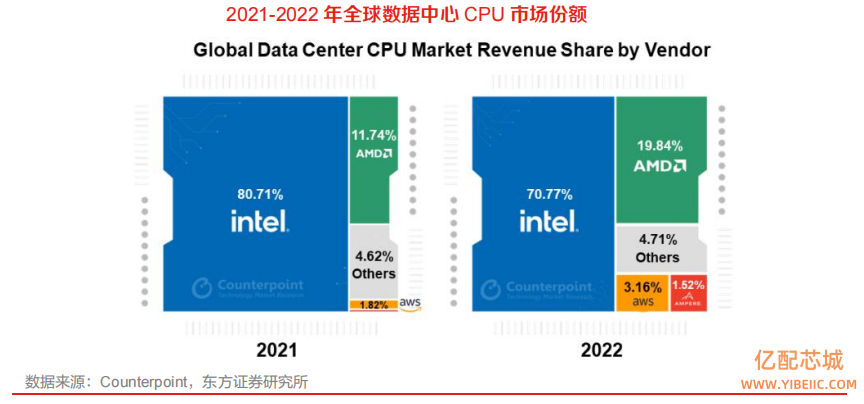
全球 GPU 市场为三足鼎立的寡头竞争格局,英伟达在独显领域一家独大。在独立显卡市场上,长期以来都是 AMD 及 NVIDIA 两家的二人转,2022 年 Intel 正式杀入了显卡市场,目前独立 GPU市场则主要由 NVIDIA、AMD 和英特尔三家公司占据,2022 年 Q4 全球独立 GPU 市场占有率分别为 85%、9%和 6%,其中,NVIDIA 在 PC 端独立 GPU 领域市场占有率优势明显。
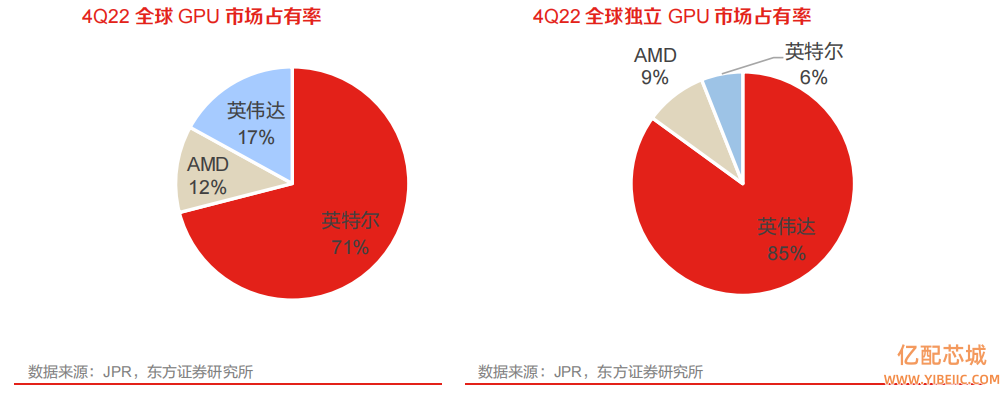
1、多数参数我国CPU具备比肩能力,但性能差距大
影响国内CPU市占率的主要是技术差异,即产品性能。CPU性能的主要影响因素为频率和IPC,其他影响 CPU 性能的因素还有总线宽度、制程、存储、内核数、封装技术等。
(1)主频,外频和倍频和 IPC。主频是 CPU 的时钟频率,即 CPU 的工作频率,一般来说,一个时钟周期完成的指令数是固定的,所以主频越高,CPU单位时间运行的指令数越多。外频即CPU和周边传输数据的频率,具体是指 CPU 到芯片组之间的总线速度,CPU 的外频决定着整块主板的运行速度。产生的输出信号频率是输入信号频率的整数倍称为倍频,倍频和外频相乘就是主频,当外频不变时,提高倍频,CPU主频也就越高。IPC指 CPU每一个频率周期里处理的指令数量。
(2)地址总线宽度。地址总线是专门用来传送地址的,CPU 通过地址总线来选用外部存储器的存储地址,总线宽度决定了 CPU 可以访问的物理地址空间(寻址能力),简单地说就是 CPU 到底能够使用多大容量的内存。例如 32 位的地址总线,最多可以直接访问 4GB 的物理空间。8 位微机的地址总线为 16 位,则其最大可寻址空间为 2^16=64KB。
(3)数据总线宽度。数据总线宽度决定了 CPU 与内存以及输入、输出设备之间一次数据传输的信息量。
(4)制程和封装。CPU 的生产需要经过硅提纯、切割晶圆、影印、蚀刻、分层、封装、测试 7个工序,制程工艺的提升或更小的制程对于 CPU 性能的提升影响明显,主要表现为 CPU 频率提升以及架构优化两个方面。一方面,工艺的提升与频率紧密相连,使得芯片主频得以提升;另一方面工艺提升带来晶体管规模的提升,从而支持更加复杂的微架构或核心,带来架构的提升。
(5)工作电压。指的是 CPU 正常工作所需的电压。低电压能够解决耗电多和发热过高的问题,使 CPU 工作时的温度降低,工作状态稳定。
(6)高速缓冲存储器。它是一种速度比内存更快的存储设备,用于缓解 CPU 和主存储器之间速度不匹配的矛盾,进而改善整个计算机系统的性能。很多大型、中型、小型以及微型计算机中都采用高速缓存。
(7)除上述性能指标外,CPU 还有其他如接口类型、多媒体指令集、装封形式、整数单元和浮点单元强弱等性能影响指标。
多数参数我国 CPU 具备比肩能力,IPC性能是最主要差距。目前通过公开信息可以看出,主频、核心数、内存类型等指标我国 CPU 厂商差异不大,具备一定的比肩能力,但落实到具体性能决定指标 IPC,仅 Intel 和 AMD 会公布 IPC“相比上一代提升了多少”,其他国产 CPU 从 IPC 性能来看大致落后于 Intel、AMD 几年水平。
2、指令级架构与生态绑定多年,创新面临知识产权等多重壁垒
指令集是 CPU 所执行的指令的二进制编码方法,是软件和硬件的接口规范。日常交流中有时也把指令集称为架构。CPU 按照指令集可分为 CISC(复杂指令集)和 RISC(精简指令集)两大类,CISC 型 CPU 目前主要是 x86 架构,RISC 型 CPU 主要包括 ARM、RISC-V、MIPS、POWER 架构等。
指令集架构与生态绑定多年,创新面临知识产权、时间等多重壁垒。历经几十年的发展,全球形成了 Wintel(Windows+Intel)和 AA(Android+ARM)两大信息化生态体系,并且都由美国主导,在生态和知识产权上都形成了自己的“领地”。中国之前没有指令集,重新搭建或者在现有的开源指令集基础上修改,会面临知识产权问题以及前期需要大量的试错优化过程。且新的指令集需要新的生态来适配,所需要的操作系统、基础软件和各种应用软件都需要重新适配,这也是目前新指令集发展的一个难点。


(1)x86 架构:主导桌面/服务器 CPU 市场
基于 CISC(复杂指令集)的 x86 架构是一种为了便于编程和提高存储器访问效率的芯片设计体系,包括两大主要特点:一是使用微代码,指令集可以直接在微代码存储器里执行,新设计的处理器,只需增加较少的晶体管电路就可以执行同样的指令集,也可以很快地编写新的指令集程式;二是拥有庞大的指令集,x86 拥有包括双运算元格式、寄存器到寄存器、寄存器到存储器以及存储器到寄存器的多种指令类型。
x86 架构主要参与者包括 Intel、AMD、海光、兆芯等。
(2)ARM 架构:崛起移动市场和 MCU 市场
ARM 架构过去称作进阶精简指令集机器,是一个 32 位精简指令集处理器架构,其广泛地使用在许多嵌入式系统设计, 电子元器件采购网 近年来也因其低功耗多核等特点广泛应用在数据中心服务器市场。早期ARM 指令集架构的主要特点:一是体积小、低功耗、低成本、高性能;二是大量使用寄存器,且大多数数据操作都在寄存器中完成,指令执行速度更快;三是寻址方式灵活简单,执行效率高;四是指令长度固定,可通过多流水线方式提高处理效率。
ARM 架构的 CPU 参与者包括飞腾、鲲鹏等,还有诸多 MCU 厂商用 ARM 架构设计相关产品,包括意法半导体、兆易创新、普冉股份、恒烁股份等。
(3)RISC-V 架构:物联网时代的新选择
RISC-V是加州大学伯克利分校设计并发布的一种开源指令集架构,其目标是成为指令集架构领域的 Linux, 主要应用 于物联 网(IoT) 领域, 但可扩展 至高性能计 算领域 。RISC-V 采用BSDLicense 发布,由于允许衍生设计和开发闭源,吸引了一大批公司的关注,目前已有不少公司开发基于 RISC-V 的 IP 核,如 Si-Five、台湾晶心、阿里平头哥等已可提供基于 RISC-V 的处理器 IP 核,部分企业如兆易创新、北京君正等已开发出基于 RISC-V 的 MCU 芯片等。但整体上,由于 RISC-V 产业生态还比较薄弱,未来的发展仍有较长一段路要走。
RISC-V 架构的参与者包括阿里平头哥,MCU 厂商包括国芯科技、赛昉科技等。
(4)MIPS 架构:在学术界影响广泛
MIPS 是高效精简指令集计算机体系结构中的一种,MIPS 的优势主要有三点:一是发展历史早,MIPS 在 1990 年代已经广泛使用在服务器、工作站设备上。二是在学术界影响广泛,计算机体系结构教材都是以 MIPS 为实际例子。三是 MIPS 在架构授权方面更为开放,授权门槛远低于 x86、ARM,在2019年曾经有开放授权的实际动作,并且 MIPS允许授权商自行更改设计、扩展指令,允许二次授权。
(5)POWER 架构:在部分汽车控制中有所应用
POWER 架构是由 IBM 设计的一种 RISC 处理器架构,POWER 在大型机领域独具优势。POWER3 是全球首款 64 位架构处理器,开始应用铜互联和 SOI(绝缘体上硅)技术。直至POWER9 依然追求最高性能,不仅具备乱序执行、智能线程等技术,还实现了 SMP(对称多处理技术)的硬件一致性处理。POWER 架构 CPU 价格高昂,主要应用于高端服务器领域,市场份额逐渐减少。
POWER 架构目前恩智浦、飞思卡尔和国芯科技的部分产品中有采用。
CPU 专用 EDA 国产替代难度大。我国的 CPU 专用 EDA 工具例如数字仿真、逻辑综合、建模、布局布线等水平比较差,长期依赖国外产品,尚无法完成完整集成电路的功能设计、综合验证和物理设计等全流程的软件工具集群,完全替换应用的难度大。
3、AI芯片的关键特征包含数据特点、计算范式、精度、重构能力等
1)新型的计算范式:控制流程简化、计算量增大
AI 计算包括传统计算和新的计算特质,处理的内容往往是非结构化数据(视频、图片等)。处理的过程通常需要很大的计算量,基本的计算主要是线性代数运算(如张量处理),而控制流程则相对简单。
2)训练和推断:需要高效的数据处理能力
AI 系统通常涉及训练(Training)和推断(Inference)过程。简单来说,训练过程是指在已有数据中学习,获得某些能力的过程;而推断过程则是指对新的数据,使用这些能力完成特定任务(比如分类、识别等)。满足高效能机器学习的数据处理要求是 AI 芯片需要考虑的最重要因素。
3)数据精度:低精度成为趋势
低精度设计是 AI 芯片的一个趋势,在针对推断的芯片中更加明显。对一些应用来说,降低精度的设计不仅加速了机器学习算法的推断(也可能是训练),甚至可能更符合神经形态计算的特征。
4、AI芯片设计趋势
1)云端训练和推断:大存储、高性能、可伸缩
存储的需求(容量和访问速度)越来越高,处理能力推向每秒千万亿次(Peta FLOPS),并支持灵活伸缩和部署。随着 AI 应用的爆发,对推断计算的需求会越来越多,一个训练好的算法会不断复用。推断和训练相比有其特殊性,更强调吞吐率、能效和实时性,未来在云端很可能会有专门针对推断的 ASIC 芯片(如 Google 的第一代 TPU),提供更好的能耗效率并实现更低的延时。
2)边缘设备:也需要具备一定的学习、本地训练能力
相对云端应用,边缘设备的应用需求和场景约束要复杂很多,针对不同的情况可能需要专门的架构设计。抛开需求的复杂性,目前的边缘设备主要是执行“推断”。在这个目标下,AI 芯片最重要的就是提高“推断”效率。目前,衡量 AI 芯片实现效率的一个重要指标是能耗效率——TOPs/W,这也成为很多技术创新竞争的焦点。未来,越来越多的边缘设备将需要具备一定的“学习”能力,能够根据收集到的新数据在本地训练、优化和更新模型。这也会对边缘设备以及整个 AI 实现系统提出一些新的要求。最后,在边缘设备中的 AI 芯片往往是 SoC 形式的产品,AI部分只是实现功能的一个环节,而最终要通过完整的芯片功能来体现硬件的效率。这种情况下,需要从整个系统的角度考虑架构的优化。因此,终端设备 AI 芯片往往呈现为一个异构系统,专门的 AI 加速器和 CPU,GPU,ISP,DSP 等其它部件协同工作以达到最佳的效率。
3)软件定义芯片:能够实时动态改变功能,满足软件不断变化的计算需求
在 AI 计算中,芯片是承载计算功能的基础部件,软件是实现 AI 的核心。这里的软件即是为了实现不同目标的 AI 任务,所需要的 AI 算法。对于复杂的 AI 任务,甚至需要将多种不同类型的 AI 算法组合在一起。即使是同一类型的 AI 算法,也会因为具体任务的计算精度、性能和能效等需求不同,具有不同计算参数。因此,AI 芯片必须具备一个重要特性:能够实时动态改变功能,满足软件不断变化的计算需求,即“软件定义芯片”。
审核编辑:黄飞
阅读全文
- 全球FPGA芯片市场布局2025-10-08
- 全球半导体收入2023年下滑11.1%,英特尔重回市场领导者地位2024-01-18